xv6第一个进程的启动过程。涉及从系统引导进kernel到kernel的初始化,然后启动第一个进程
上一节系统引导分析了整个引导过程,接下来从kernel入口_start(entry.S)往下分析,主要
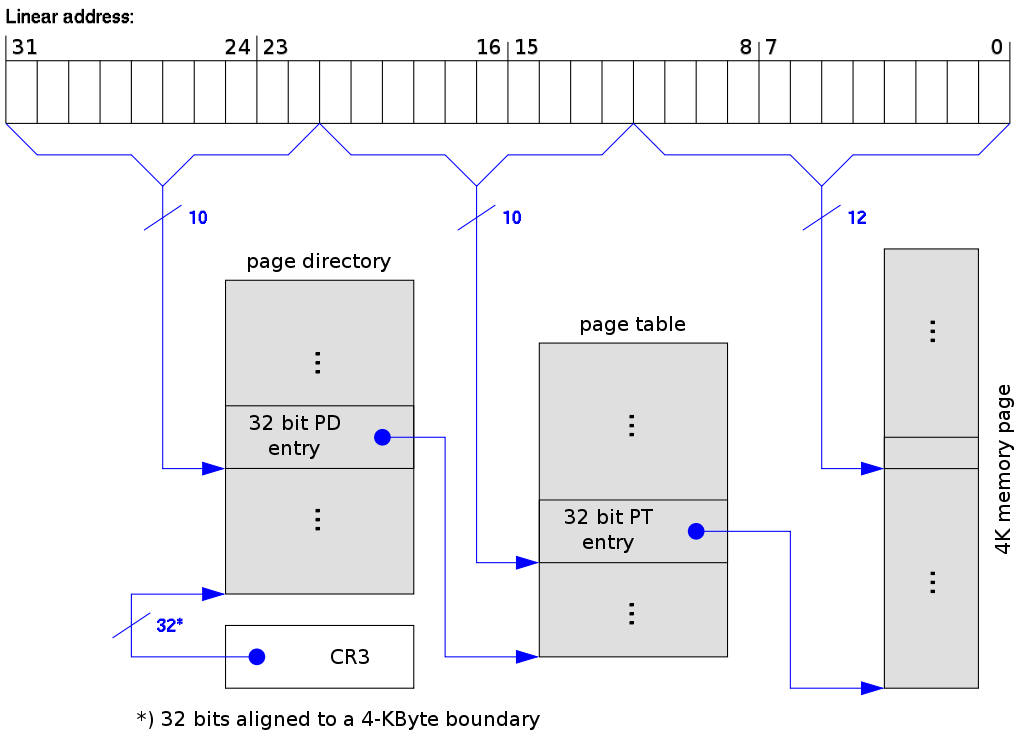
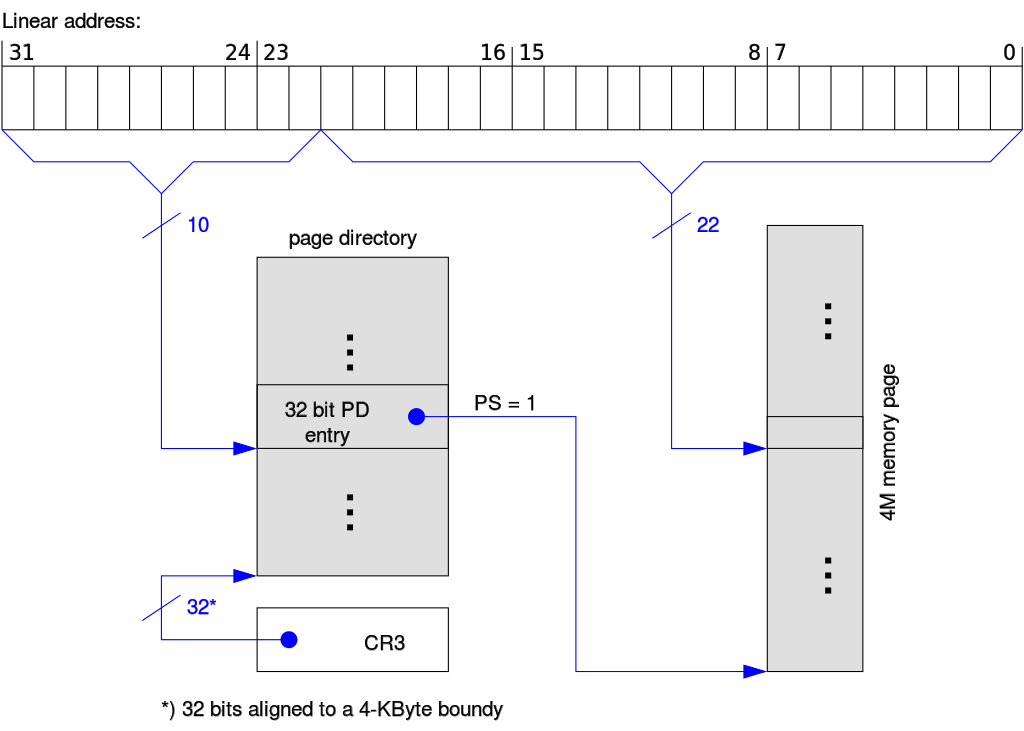
启动分页 分页机制或者说MMU是什么不作介绍,这里说下分页机制的一些必要操作。
在x86中,一个也目录中可以同时存在两种粒度的内存页,4K或者4M,
page dir是必须的,这是一个长度最大 为1024的整数数组,如果页目录表项的PS位置为1
注意x86运行两种分页同时存在,比如cr4的PSE位设为1,而有些page dir表项设置PS位而有些
对于xv6来说,使用4M页只是临时,不用创建复杂的页表,如此而已,
entry.S 1 .globl _start
_start = V2P_WO(entry) # kernel的入口仍然是低地址值,因为此时分页还没有开启
# Entering xv6 on boot processor, with paging off.
.globl entry
entry:
# 设置cr4,使用4M页,这样创建的页表比较简单
movl %cr4, %eax
orl $(CR4_PSE), %eax
movl %eax, %cr4
# 设置cr3
movl $(V2P_WO(entrypgdir)), %eax
movl %eax, %cr3
# 启动分页
movl %cr0, %eax
orl $(CR0_PG|CR0_WP), %eax
movl %eax, %cr0
# 创建CPU栈,这个是该CPU独有的,启动其他CPU时,每个都自己的stack
movl $(stack + KSTACKSIZE), %esp
# 进入高地址空间(2GB以上)
mov $main, %eax
jmp *%eax
# common symbol,开辟stack区域,大小为KSTACKSIZE
.comm stack, KSTACKSIZE
我们来看看页目录entrypgdir是什么样子的,
main.c 1 2 3 4 5 6 pde_t entrypgdir[NPDENTRIES] = { [0 ] = (0 ) | PTE_P | PTE_W | PTE_PS, [KERNBASE>>PDXSHIFT] = (0 ) | PTE_P | PTE_W | PTE_PS, };
疑问:为何要将0~4M进行1:1映射呢?在开启分页之前我们都是小心翼翼的使用“低地址”,
内核初始化 到现在为止,只有boot CPU在运转,其他CPU需要boot CPU去启动才行,在启动之前,boot
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int main (void ) kinit1(end, P2V(4 *1024 *1024 )); kvmalloc(); mpinit(); lapicinit(); seginit(); cprintf("\ncpu%d: starting xv6\n\n" , cpu->id); picinit(); ioapicinit(); consoleinit(); uartinit(); pinit(); tvinit(); binit(); fileinit(); iinit(); ideinit(); if (!ismp) timerinit(); startothers(); kinit2(P2V(4 *1024 *1024 ), P2V(PHYSTOP)); userinit(); mpmain(); }
初始化部分其实是很复杂的,牵涉到各个部分,现在我们只是简单的提及,后续做详细介绍。kinit1(),初始化end~4MB这一段内存,这样kalloc()就能分配出内存来了。kvmalloc()重建内核页表并设置cr3切换到该页表,该页表会把IO空间,内核镜像等都建立
vm.c 1 2 3 4 5 6 7 8 9 10 11 static struct kmap { void *virt; uint phys_start; uint phys_end; int perm; } kmap[] = { { (void *)KERNBASE, 0 , EXTMEM, PTE_W}, { (void *)KERNLINK, V2P(KERNLINK), V2P(data), 0 }, { (void *)data, V2P(data), PHYSTOP, PTE_W}, { (void *)DEVSPACE, DEVSPACE, 0 , PTE_W}, };
seginit()初始化段寄存器,注意,logical address指的是”段内地址”,
vm.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 cpus[] --> +------------------------+ +---------+ <-- %gs of CPU0 | | | %gs:0~3 | | ...... | +---------+ | | | %gs:3~7 | +---> +------------------------+ +---------+ | | uchar id | | | struct context* | +---------+ <-- %gs of CPU1 | | struct segdesc gdt[] | +-------+ | %gs:0~3 | | | ...... | | +---------+ | +------------------------+ | +-----+ | %gs:3~7 | +---- | struct cpu *cpu | <----+ | +---------+ +------------------------+ | | struct proc *proc | <------+ +------------------------+ +---------+ <-- %gs of CPU2 | | | %gs:0~3 | | ...... | +---------+ | | | %gs:3~7 | +------------------------+ +---------+ */ void seginit (void ) struct cpu *c; c = &cpus[cpunum()]; c->gdt[SEG_KCODE] = SEG(STA_X|STA_R, 0 , 0xffffffff , 0 ); c->gdt[SEG_KDATA] = SEG(STA_W, 0 , 0xffffffff , 0 ); c->gdt[SEG_UCODE] = SEG(STA_X|STA_R, 0 , 0xffffffff , DPL_USER); c->gdt[SEG_UDATA] = SEG(STA_W, 0 , 0xffffffff , DPL_USER); c->gdt[SEG_KCPU] = SEG(STA_W, &c->cpu, 8 , 0 ); lgdt(c->gdt, sizeof (c->gdt)); loadgs(SEG_KCPU << 3 ); cpu = c; proc = 0 ; } extern struct cpu *cpu asm ("%gs:0" ) extern struct proc *proc asm ("%gs:4" )
启动多处理器 多处理器的启动是通过IPI,即Inter-Processor Instructions进行的,这是CPU间的通讯方式。startothers()来启动其他non-boot CPU,做法是:
复制启动代码到0x7000处,这部分代码相当于boot CPU的启动扇区代码
为每个AP分配stack(是的,每个CPU都一个自己的stack)
告诉每个AP,kernel入口在哪里(mpenter函数)
告诉每个AP,页目录在哪里(entrypgdir)
然后控制local apic进行CPU间通讯,依次启动其他CPU。启动之后他们会执行mpenter(),进而进入
启动init进程 boot CPU启动其他CPU之后,自己继续执行kinit2()初始化剩余的内存空间,然后开始启动init进程。userinit()中,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void userinit (void ) struct proc *p; extern char _binary_initcode_start[], _binary_initcode_size[]; p = allocproc(); initproc = p; if ((p->pgdir = setupkvm()) == 0 ) panic("userinit: out of memory?" ); inituvm(p->pgdir, _binary_initcode_start, (int )_binary_initcode_size); p->sz = PGSIZE; memset (p->tf, 0 , sizeof (*p->tf)); p->tf->cs = (SEG_UCODE << 3 ) | DPL_USER; p->tf->ds = (SEG_UDATA << 3 ) | DPL_USER; p->tf->es = p->tf->ds; p->tf->ss = p->tf->ds; p->tf->eflags = FL_IF; p->tf->esp = PGSIZE; p->tf->eip = 0 ; safestrcpy(p->name, "initcode" , sizeof (p->name)); p->cwd = namei("/" ); p->state = RUNNABLE; }
创建进程数据结构 首先创建进程数据结构,然后初始化,并设其状态为RUNNABLE,等待进入scheduler()allocproc()函数,它在全局变量ptable中寻找UNUSED的进程结构,
proc.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 if ((p->kstack = kalloc()) == 0 ){ p->state = UNUSED; return 0 ; } sp = p->kstack + KSTACKSIZE; sp -= sizeof *p->tf; p->tf = (struct trapframe*)sp; sp -= 4 ; *(uint*)sp = (uint)trapret; sp -= sizeof *p->context; p->context = (struct context*)sp; memset (p->context, 0 , sizeof *p->context);p->context->eip = (uint)forkret; return p;
每个进程的创建都是这样的,不论是init进程还是fork创建的普通进程。进程的内核栈到底什么样子呢,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 进程的kernel stack初始化状态, / +---------------+ <-- stack base(= p->kstack + KSTACKSIZE) | | ss | | +---------------+ | | esp | | +---------------+ | | eflags | | +---------------+ | | cs | | +---------------+ | | eip | <-- 从此往上部分,在iret时自动弹出到相关寄存器中,只需把%esp指到这里即可 | +---------------+ | | err | | +---------------+ | | trapno | | +---------------+ | | ds | | +---------------+ | | es | | +---------------+ | | fs | struct trapframe | +---------------+ | | gs | | +---------------+ | | eax | | +---------------+ | | ecx | | +---------------+ | | edx | | +---------------+ | | ebx | | +---------------+ | | oesp | | +---------------+ | | ebp | | +---------------+ | | esi | | +---------------+ | | edi | \ +---------------+ <-- p->tf | trapret | / +---------------+ <-- forkret will return to | | eip(=forkret) | <-- return addr | +---------------+ | | ebp | | +---------------+ struct context | | ebx | | +---------------+ | | esi | | +---------------+ | | edi | \ +-------+-------+ <-- p->context | | | | v | | empty | +---------------+ <-- p->kstack */
当然,这样的初始化结果是经过精心设计的,比如trapret()、forkret()函数地址的设置。
注意trapframe里的eip正是进入用户态之后执行的程序的入口,init进程跟普通进程
构建进程地址空间 接下来为进程创建页目录,也就是构建进程地址空间,这里会把kernel也映射到
vm.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 void inituvm (pde_t *pgdir, char *init, uint sz) char *mem; if (sz >= PGSIZE) panic("inituvm: more than a page" ); mem = kalloc(); memset (mem, 0 , PGSIZE); mappages(pgdir, 0 , PGSIZE, v2p(mem), PTE_W|PTE_U); memmove(mem, init, sz); }
进入调度器开始执行 boot CPU继续执行进入scheduler()函数,它线性遍历ptable寻找
开始执行进程p 1 2 3 4 5 6 7 8 9 10 proc = p; switchuvm(p); p->state = RUNNING; swtch(&cpu->scheduler, proc->context); switchkvm(); proc = 0 ;
进程数据结构创建之后就做好准备被调度了,在scheduler()中,首先要进行user vmswitchuvm(p),它会设置TSS段并且将其中的ss0设置为SEG_KDATA,把ltr(SEG_TSS<<3),这会让CPU在执行iret时使用该TSS的内容。设置ss0, esp0
然后切换到进程页目录,注意,因为kernel空间也映射进用户也目录了,swtch(),
swtch.S 1 .globl swtch
swtch:
movl 4(%esp), %eax # cpu context
movl 8(%esp), %edx # proc context
# Save old callee-save registers
# 旧的context进栈,进的是是CPU的栈,不是进程内核栈
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
# Switch stacks
movl %esp, (%eax) # %esp此时执行上面四个寄存器信息,现在给cpu的context变量赋值
movl %edx, %esp # %esp指向新的proc的context,上图中的p->context
# Load new callee-save registers
popl %edi
popl %esi
popl %ebx
popl %ebp
# popl之后,剩下的是eip,见上图,ret会返回"ret addr"处继续执行,也就是返回到forkret()继续执行
ret
forkret()启动了一个log之后就返回了,接下来在栈中的是trapret()的地址,于是返回到trapret()
trapasm.S 1 .globl trapret
trapret:
popal
popl %gs
popl %fs
popl %es
popl %ds
addl $0x8, %esp # trapno and errcode
iret
继续看上面的图,popal弹出一堆寄存器值,popl又弹出一堆,然后addl $0x8, %esp越过eip了(见struct trapframe),然后iret(interrupt return),eip指定的地址继续执行,回到userinit()函数,
1 2 3 4 5 6 7 8 9 memset (p->tf, 0 , sizeof (*p->tf));p->tf->cs = (SEG_UCODE << 3 ) | DPL_USER; p->tf->ds = (SEG_UDATA << 3 ) | DPL_USER; p->tf->es = p->tf->ds; p->tf->ss = p->tf->ds; p->tf->eflags = FL_IF; p->tf->esp = PGSIZE; p->tf->eip = 0 ;
我们回到用户空间的0处执行,而此处已经被inituvm()放置上initcode.S的内容了,/init程序而已。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 init进程的内存布局: +--------------------+ 4GB | | | | | | +--------------------+ KERNBASE+PHYSTOP(2GB+224MB) | | | direct mapped | | kernel memory | | | +--------------------+ | Kernel Data | +--------------------+ data | Kernel Code | +--------------------+ KERNLINK(2GB+1MB) | I/O Space(1MB) | +--------------------+ KERNBASE(2GB) | | | | | | | | | | | | | | | | +---------+----------+ PGSIZE <-- %esp | v | | stack | | | | | | initcode.S | +--------------------+ 0 <-- %eip */
(over)