JamVM的解释器实现,以及常见解释器实现方法。
解释器的常见实现方案
什么是代码(code)?代码不过是指令和参数的集合。以Java字节码为例,所有指令都用一个
字节来表示,即一个指令就是一个0~255之间的整数,代码也可以看作是字节数组。
解释器的工作非常简单:解释字节码并返回结果。
字节码一般都会有一个指令集,就像CPU的指令集一样,所以解释器会针对每一个指令创建一个
代码片段(code stub, handler)。执行的时候,解释器只需拿到指令,转到对应的代码片段执行并得到
结果,然后转到下一个指令,这个过程也叫做代码分发(code disptch)。
解释器的设计就集中在两点:
- 两个指令之间的转换
- 字节码是逐条执行还是直接翻译为机器码(inline dispatch)
针对指令之间的跳转方法,解释器有如下几种方案:
- 使用一个无限循环以及一个switch完成跳转(switch-based dispatch)
- 使用一个跳转表,将字节码指令翻译为实际代码片段地址(indirect dispatch)
- 先将字节码指令翻译为代码片段地址,执行的时候直接跳转(direct dispatch)
下面各个分发策略大量参考了这个博文,另外这篇博文也是非常好的讲解,并且它
还附带几种常见分发策略的具体实现以及对比。
基于switch的分发策略
既然指令就是一个整数,我们就可以用一个大大的switch语句来分发指令了,
1 | // 定义指令集 |
好了,这就是一个简单的解释器的雏形,但是它有一个致命的缺点:CPU的分支预测功能被彻底去掉了。
直接跳转分发策略
为了利用CPU的分支预测功能,我们引入直接跳转策略,
1 | // 注意这里的代码已经不再是 作为整数的指令了,所以需要提前把 |
直接跳转策略一个缺点就是它需要提前把指令码转换为handler的内存地址。
间接跳转分发策略
正所谓
任何问题都可以通过添加一个layer来解决。
我们这里也是,通过增加一个跳转表,就可以不用跟直接跳转那样提前转换指令码了,
1 | // lookup table, 跳转表 |
inline分发策略
inline策略大致思想是把字节码程序转换为机器码,然后直接执行机器码,这个不就是JIT吗?!
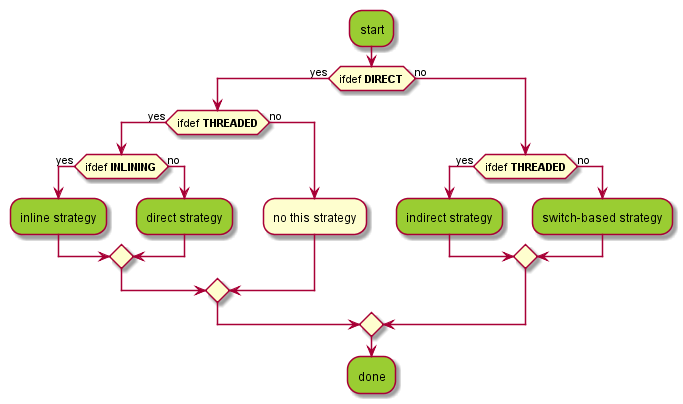
JamVM中的分发策略实现
JamVM支持switch-based策略、间接跳转策略、直接跳转策略以及Inline策略。这些策略通过
三个宏控制:DIRECT, THREADED, INLINING。
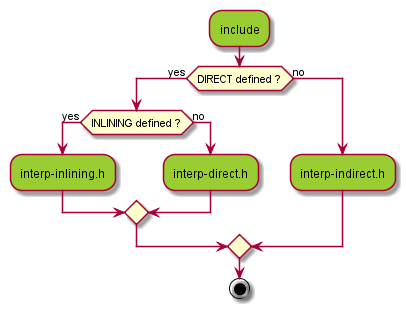
各种分发策略所在的头文件,
所有策略的代码实现均位于src/interp/engine/interp.c中,而这些实现基本都集中在uintptr_t *executeJava();函数中。该函数大量使用宏来生成代码,宏在不同的分发策略下
对应不同的代码生成方式,这样就可以通过这些宏来自由的切换分发策略。
executeJava()函数的结构
这个函数结构简单,但是代码复杂,其中掺杂大量宏代码,以期在各个分发策略之间灵活切换。
该函数结构如下:
- 定义解释器,如indirect策略中定义跳转表
- 准备解释器的执行环境如取得函数帧、操作数栈、局部变量表、常量池等资源
- 创建代码分发器
- 开场,创建代码分发器头部,如switch-based策略下创建switch语句开头部分
- 创建指令码handler,如switch-based策略下创建各个指令码对应的case语句
- 结尾,结束代码分发器,如switch-based策略下结束switch语句以及结束函数
定义解释器和代码分发器的三个部分基本都是由宏构成的,只需根据分发策略来定义这些宏即可。
宏定义分析
direct策略没有non-threading的,所以开启direct策略的必须打开threading功能,而
non-threading的indirect策略也即switch-based策略是非常简单的,故宏定义直接分析
threading部分。
什么是threading code?
switch策略把每个指令孤立起来了,每个指令都从头来一遍,这对CPU的分支预测是极其
不利的,所以我们需求一种方式使得各个指令能够串联成一条线执行下去,这样的代码
就是threading code,即串联起来的代码,或者叫做代码串联。
回到代码分发策略,要想把代码串联起来,indirect策略使用了一个跳转表,即每次执行完
一条指令之后,查找跳转表找到下一条指令的地址,然后跳转过去执行;而direct策略则是
在代码执行之前,首先把指令码转码成本地代码(即指令码对应的C代码)内存地址,然后执行,
从而省略了查表的过程,但是在转码的时候仍然需要一个跳转表。所以无论如何,只要打开
threading功能就需要一个跳转表,即threading的本质其实就是构建一个跳转表。这样,再
看看interp-threading.h的内容,它里面定义的宏其实就是做了一件事:构建跳转表。
1 | #define TBL_NAME(level, label) handlers_##level##_##label |
这就是跳转表的定义,其中的level用于代码缓存,而label用于inline策略,
如果不是inline策略且关闭代码缓存的话,level默认为0,label默认为ENTRY。
宏L、X、D、I、J用于特殊指令的支持与否,如支持JSR292那么使用J定义的
表项就有定义,否则就用unused来替代。
interp-threading.h把跳转表定义好了,但是表项里保存的是handler的地址,
那么handler要在哪里定义呢?当然是各个策略根据自己的需要定义handler,如
switch-based策略的handler其实是一些case语句,而其他支持threading的策略
则是一些形如:
1 | opc_OPCODE_LEVEL_LABEL: |
这样的代码,这些代码同样是通过宏来定义,在executeJava()函数的“创建指令
handler”部分会调用这些指令,无论哪种策略,它们都有统一的格式:
1 | // 如indirect threading策略中的定义,interp-indirect.h,它的label只用到 |
好了,有了跳转表定义,在executeJava()函数的“定义跳转表”部分,只需使用宏定义跳转表即可,
而定义handler的宏也有了,在“创建指令码handler”部分使用这些宏即可定义handler。剩下的就是
代码分发器的“开场”和“结尾”的宏定义,这两部分相对简单,比如switch-base策略的开场只需如此,
1 | while(1) { |
而结尾部分只是把两者闭合,
1 | } /* end of switch(*pc++) */ |
类似的,对于直接跳转和简介跳转,开场部分只是把pc设为method block的code部分,然后跳转到
那里,而结尾部分就是method return,以此来结束method的执行。
direct策略的转码部分
inline策略的代码翻译部分
(to be continued)